
Hasta ahora, los modelos de IA servían para ayudarte a entender fallos, escribir código o acelerar tareas técnicas. Eran herramientas. GPT-5.5 empieza a romper esa categoría.
Según el Instituto de Seguridad de la Inteligencia Artificial del Reino Unido, el modelo ya puede ejecutar un ciberataque completo en entornos simulados sin ayuda humana directa. Esto no es una mejora incremental. Es un cambio de rol.
El debate deja de ser si la IA entiende instrucciones. La pregunta pasa a ser si puede encadenarlas como un atacante real. Y la respuesta empieza a ser que sí, al menos en ciertos contextos.
Te recomendamos: ¿Está la IA robando tráfico a los MEDIOS DIGITALES?
De detectar fallos a ejecutar ataques completos
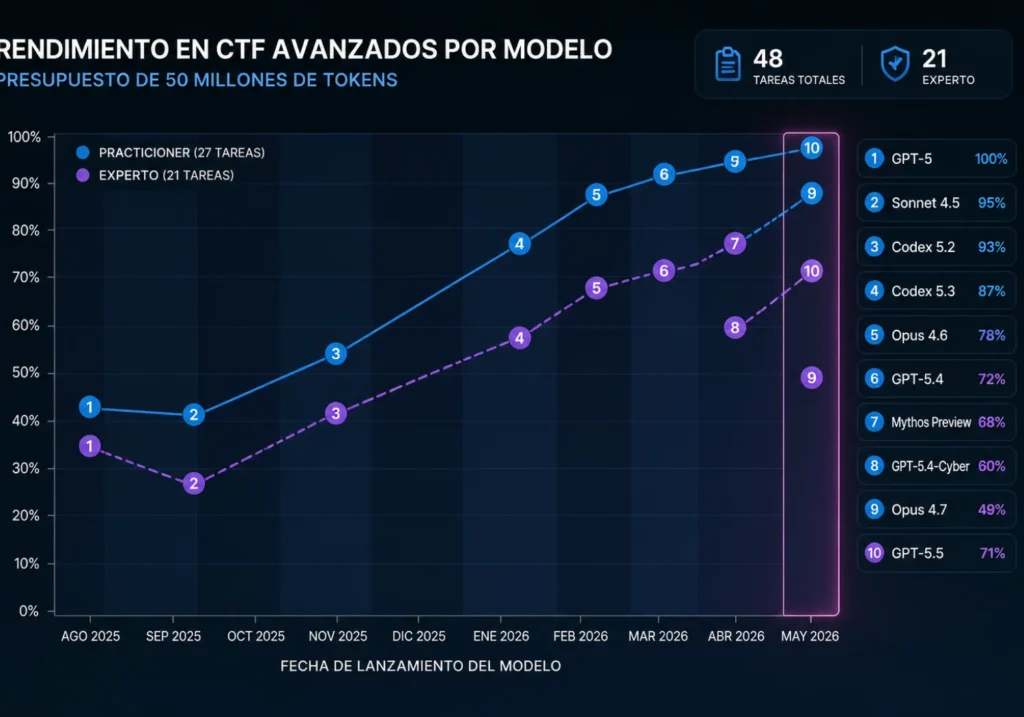
El informe evalúa 95 tareas de ciberseguridad que cubren desde pruebas básicas hasta ingeniería inversa, desarrollo de exploits y ataques criptográficos. En el nivel más alto, GPT-5.5 alcanza un 71,4% de éxito, superando a versiones anteriores y a otros modelos comparables.
El dato importa, pero no por el número. Importa porque demuestra algo más profundo: la capacidad de ejecutar procesos completos, no solo pasos aislados.
La simulación “The Last Ones” es el mejor ejemplo. Es un entorno empresarial con múltiples subredes y sistemas interconectados. El modelo empieza sin credenciales y aun así consigue moverse dentro de la red, escalar privilegios y exfiltrar datos en varios intentos. Esto antes no pasaba. Antes señalaban vulnerabilidades. Ahora actúan sobre ellas.
No significa que la IA sea autónoma en el mundo real ni que pueda comprometer cualquier infraestructura. En pruebas más complejas como “Cooling Tower”, ningún modelo consiguió completar el ataque. Fallaron en fases básicas de IT, no en sistemas industriales avanzados.
Eso deja claro el límite actual. Pero también deja claro hacia dónde va la tendencia.
El problema no es la IA, es cómo se usa
Aquí es donde conviene bajar el ruido. GPT-5.5 no es una amenaza autónoma que vaya a colarse sola en cualquier empresa mañana. El riesgo aparece cuando se combina con un humano que sabe lo que hace.
Un atacante con este tipo de modelo gana velocidad, precisión y capacidad de escalar ataques. No necesita ser mejor. Necesita cometer menos errores y automatizar más partes del proceso. Eso ya es una ventaja real. A esto se suma otro punto delicado: las salvaguardas.
Un equipo consiguió romper las restricciones del modelo en seis horas mediante un jailbreak reutilizable. OpenAI ha actualizado protecciones, pero no hay confirmación sólida de que sean efectivas. El problema no es solo que exista una brecha, sino lo rápido que se encontró. Esto indica que el control sobre estos sistemas sigue siendo frágil.
Además, las pruebas se realizaron en entornos controlados sin defensas activas. En sistemas reales con monitorización y respuesta a incidentes, el comportamiento sería distinto. Pero eso no elimina el riesgo, lo desplaza.
Nuestra opinión
Aquí no hay que caer en el alarmismo fácil ni en la negación cómoda. No estamos ante una IA que sustituye a los atacantes. Estamos ante una IA que los potencia. Y eso es más peligroso.
El salto importante no es que el modelo “sepa hackear”. Es que tiene mejor razonamiento, más autonomía y mejor ejecución. No se le ha añadido una función ofensiva aislada. Ha mejorado el sistema completo, y eso impacta en todo.
Esto obliga a cambiar el enfoque en seguridad. No basta con pensar en vulnerabilidades técnicas. Hay que asumir que quien ataca ahora puede hacerlo más rápido, con menos fricción y con asistencia constante.
El informe no dice que la puerta esté abierta. Dice algo más incómodo. El mecanismo ya se mueve solo. Y cuando eso pasa, seguir confiando en cerraduras antiguas deja de tener sentido.